Podcasts of Neil Patel, Eric Ward, and Vanessa Fox
I’ve been interviewing speakers of the AMA’s Hot Topic: Search Engine Marketing events taking place April 20th in San Francisco, May 25th in NYC, and June 22 in Chicago (all three of which I will be chairing). I had fascinating and insightful conversations with link builder extraordinaire Eric Ward, Googler Vanessa Fox, and social media marketing guru Neil Patel. There’s some real gold in those interviews.
Download/Listen:
- Neil Patel interview (15 minute MP3, 3 megs) – getting to the front page of Digg and other social media sites
- Eric Ward interview (36 minute MP3, 8 megs) – tips and secrets on how to garner links
- Vanessa Fox interview (40 minute MP3, 9 megs) – Google’s webmaster tools, SEO impacts of AJAX, Flash, duplicate content, redirects, etc.
More podcasts to come from other speakers, so be sure to subscribe to the RSS feed so you don’t miss them. Also be sure to register for the conference at one of the three cities, it’ll be great!
Possible Related Posts
Posted by stephan of stephan on 03/28/2007
Permalink | |  Print
| Trackback | Comments Off on Podcasts of Neil Patel, Eric Ward, and Vanessa Fox | Comments RSS
Print
| Trackback | Comments Off on Podcasts of Neil Patel, Eric Ward, and Vanessa Fox | Comments RSS
Filed under: Google, Link Building, SEO, Site Structure, Social Media Optimization digg, Google, Link Building, link-baiting, podcasts, Social Media Optimization, social-media-marketing, Webmaster-Central
Google Logo with Autographs
 While I was vacationing in St. Louis last week, I stumbled across this curiosity — the Google logo with Larry Page’s and Sergey Brin’s signatures.
While I was vacationing in St. Louis last week, I stumbled across this curiosity — the Google logo with Larry Page’s and Sergey Brin’s signatures.
This is the Google logo from 2004, commemorating SpaceShipOne winning the Ansari X-Prize.
Possible Related Posts
Posted by Chris of Silvery on 03/20/2007
Permalink | | Print
| Trackback | Comments Off on Google Logo with Autographs | Comments RSS
Filed under: Google Ansari-X-Prize, Burt-Rutan, Google, Google-Logo, larry-page, Sergey-Brin, SpaceShipOne
Google Employees Can’t Find PageRank – Must Search For It
Last night, I was comparing relative popularity of a few keywords in Google Trends, and I noticed that the term, “PageRank”, apparently has the highest number of searches in the US from people in the city of Mountain View, California:
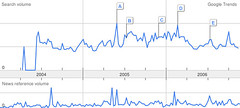

http://www.google.com/trends?q=pagerank&ctab=0&geo=US&date=all
As you may be aware, Google headquarters is located in Mountain View (see map).
So the most likely reason that most USÂ “PageRank” searches happen in that little town is that Google employees are frequently submitting searches for info about PageRank. They may be searching for what people are saying about PageRank, or they may be searching for new research papers concerning the algorithm. But, they’re definitely searching for it…
For the one place in the world that has the most PageRank of all, you’d think they wouldn’t have to search for it. 😉
Â
Â
Possible Related Posts
Posted by Chris of Silvery on 02/23/2007
Permalink | | Print
| Trackback | Comments Off on Google Employees Can’t Find PageRank – Must Search For It | Comments RSS
Filed under: Google, PageRank Google, Google-Trends, PageRank
Google Developing Artificial Intelligence (AI) – Brave New World
Google’s Larry Page addressed the recent conference for the American Association for the Advancement of the Sciences, and in his presentation he revealed what many of us had suspected or already knew from some of our friends who are employees within the company: researchers in Google are working upon developing Artificial Intelligence (aka “AI”).
During the address, Page stated he thought that human brain algorithms actually weren’t all that complicated and could likely be approximated with sufficient computational power. He said, “We have some people at Google (who) are really trying to build artificial intelligence and to do it on a large scale. It’s not as far off as people think.” Well, one of the top scientists in the world disagrees, if he’s talking about approximating a human-like consciousness.
I’ve written previously about how stuff predicted in cyberpunk fiction is becoming reality, and how Google might be planning to develop intelligent ‘search pets’ which would directly integrate with the human brain in some fashion. What might Google use this for and how soon might they show it to the world? Read on…
Possible Related Posts
Posted by Chris of Silvery on 02/20/2007
Permalink | | Print
| Trackback | Comments Off on Google Developing Artificial Intelligence (AI) – Brave New World | Comments RSS
Filed under: Futurism, Google A-Scanner-Darkly, ai, artificial-intelligence, craig-silverstein, Futurism, Google, larry-page, science-fiction, Turing-tests
Hey Google: Nofollow is for when I don’t vouch for the link’s quality
I’ve said before that I don’t agree with Google’s tough stance on link buying and use of “nofollow” to mark it as a financially influenced link (here and here). One of my favorite white-hat SEO bloggers, Rand Fishkin, is also on Google’s case for it. A key argument that Rand makes:
Nofollow means “I do not editorially vouch for the quality of this link.” It does NOT mean “financial interest may have influenced my decision to link.” If that were the case, fully a quarter of all links on the web would require nofollow (that’s a rough guess, but probably close to the mark). Certainly any website that earns money via its operation, directly or indirectly is guilty of linking to their own material and that of others in the hopes that it will benefit them financially. It is not only unreasonable but illogical to ask that webmasters around the world change their code to ensure that once the chance of financial benefit reaches a certain level (say, you’re about 90% sure a link will make you some money), you add a “nofollow” onto the link.
You go, Rand! Tell those Googlers a thing or two! 😉
Despite all this, Google is the one who holds the keys to the kingdom. So we have to abide by their rules, no matter how “unreasonable” and “illogical.” That’s why my January column for Practical Ecommerce goes into some detail explaining Google’s stance on link buying and the risks. I’ll post a link once the article comes out in a few days.
Possible Related Posts
Posted by stephan of stephan on 12/28/2006
Permalink | | Print
| Trackback | Comments Off on Hey Google: Nofollow is for when I don’t vouch for the link’s quality | Comments RSS
Filed under: Google, Link Building Google, link-buying, nofollow
Interview with Google about duplicate content
The following is an excerpt of a video conversation held between Vanessa Fox, Product Manager of Google Webmaster Central, and Rand Fishkin, CEO and co-founder of SEOMoz about Google and duplicate content. This further confirms Adam Lasnik’s position that it’s a filter, not a penalty. The full video can be found here.
Rand Fishkin: Duplicate content filter, is that the same or different to a duplicate content penalty?
Vanessa Fox: So I think there is a lot of confusion about this issue. I think people think that if Google sees information on a site that is duplicate within the site then there will some kind of penalty applied (duplicating its own material). There’s a couple of different ways this can happen, one if you use subpages that seem to have a lot of content that is the same, e.g. a local type site that says here is information about Boulder and here’s information about Denver, but it doesn’t actually have any information about Boulder, it just says Boulder in one place and Denver in the other. But otherwise the pages are exactly the same. Another scenario is where you have multiple URL’s that point to the same exact page, e.g. a dynamic site. So those are two times when you have duplicate content within a site.Fishkin: So would you call that a filter or would you call that a penalty, do you discriminate between the two?
Fox: There is no penalty. We don’t apply any kind of penalty to a site that has that situation. I think people get more worried than they should about it because they think oh no, there’s going to be a penalty on my site because I have duplicate content. But what is going to happen is some kind of filtering, because in the search results page we want to show relevant, useful pages instead of showing ten URLs that all point to the same page – which is probably not the best experience for the user. So what is going to happen is we are going to only index one of those pages. So if you don’t care, in the instance where there are a lot of URLs that all point to the same exact page, if you don’t care which one of them is indexed then you don’t have to do anything, Google will pick one and we’ll index it and it will be fine.Fishkin: So let’s say I was looking for the optimal Google experience and I was trying to optimize my site to the best of my ability, would I then say well maybe it isn’t so good for me to have Google crawling my site pages I know are duplicates (or very similar), let me just give them the pages I know they will want?
Fox: Right, so you can do that, you can redirect versions…we can figure it out, it’s fine, we have a lot of systems. But if you care which version of the site is indexed, and you don’t want us to hit your site too much by crawling all these versions, then yeah, you might want to do some things, you can submit sitemaps and tell us which version of the page you want, you can do a redirect, you can block with robots, you can not serve us session IDs. I mean there’s a lot of different things you could do in that situation. In the situation where the pages are just very similar, it’s sort of a similar situation where you want to make the pages as unique as possible. So that’s sort of a different solution to the similar sort of problem. You want to go, ok, how can I make my page about Boulder, different from my page about Denver, or maybe I just need one page about Colorado if I don’t have any information about the other two pages.
Possible Related Posts
Posted by Gabriel of Gabriel on 12/28/2006
Permalink | | Print
| Trackback | Comments Off on Interview with Google about duplicate content | Comments RSS
Filed under: Google duplicate-content, duplicate-pages, Google, Vanessa-Fox, Webmaster-Central
Google, Yahoo & MicroSoft to Cooperate on Sitemaps
I was delighted today that the Google and Yahoo search engines announced at PubCon that they would jointly support and collaborate upon one protocol for webmasters to use for submitting their site URLs for potential inclusion. View the video of the announcement here. MicroSoft has also apparently agreed to use the same protocol as well.
To support this initiative, they will jointly support sitemaps.org. If you recall, “sitemaps” was the product name that Google had been using, and which became deprecated just a few months ago in favor of “Google Webmaster Tools”. Obviously, the wheels had already begun turning to repurpose the “Sitemaps” brand name into a jointly-operated service.
Now when Sitemaps are generated to follow the common protocol, webmasters will still need to submit the link feeds to each of the SEs via their existing managment tools such as in Google Webmaster Tools and in Yahoo! Site Explorer.
If you recall, I was one of a number of webmasters out there who had requested that they collaborate on a common protocol, such as in a blog post I wrote back in September:
“Hopefully each of the major search engines will try to employ identical or compatible formats for site URLs, because it will be a hassle to have to keep up with multiple formats. This is an area where the SEs really ought to cooperate with one another for “pro bono publicoâ€? – for the common good. Currently, Yahoo seems to be just defensively immitating Google in this arena, and no one’s showing signs of collaborating.”
Kudos to Google and Yahoo for overcoming traditional corporate competitiveness to do something that mutually benefits website owners as well as the search engines!
Â
Possible Related Posts
Posted by Chris of Silvery on 11/16/2006
Permalink | | Print
| Trackback | Comments Off on Google, Yahoo & MicroSoft to Cooperate on Sitemaps | Comments RSS
Filed under: Google, MSN Search, Tools, Yahoo Google, msn, Site-Explorer, site-submission, Sitemaps, Yahoo
SEO May Be Eclipsed by User-Centered Design
I’ve been seeing indications that Google has shifted their weighting of the ~200 various signals they use in their ranking soup over the past couple of years. It used to be that PageRank along with the number of keyword references on a page were some of the strongest signals used for what page comes up highest in the search results, but I’ve seen more and more cases where PageRank and keyword density seem relatively weaker than they once were. I see a lot of reasons to believe that quality ratings have become weighted more heavily for rankings, particularly among more popular search keywords. Google continues to lead the pack in the search marketplace, so their evolution will likely influence their competitors in similar directions, too.
So, what is my evidence that Google’s development of Quality criteria is becoming more influential in their rankings than PageRank and other classic optimization elements? Read on and I’ll explain. (more…)
Possible Related Posts
Posted by Chris of Silvery on 11/15/2006
Permalink | | Print
| Trackback | Comments Off on SEO May Be Eclipsed by User-Centered Design | Comments RSS
Filed under: Best Practices, Design, Google, PageRank, Search Engine Optimization, SEO, Yahoo Google, IndyRank, SEO, TrustRank, usability, User-Centered-Design, Yahoo
Nouveau Meta Tags for SEO
Back in the earliest days of search optimization, meta tags were a great channel for placing keywords for the search engines to associate with your pages. A meta tag does just what it sounds like — they are the html tags built to hold metadata (or, “data describing the data”) about pages. In terms of SEO, the main meta tags people refer to are the Keywords and Description meta tags. Meta tags are not visible to endusers looking at the page, but the meta tag content would be collected by search engines and used to rank a page — it was really convenient if you wanted to pass synonyms, misspellings, and various term stems along with the specific keywords.

Immediately after people realized that meta tags could allow a page to be found more relevant in the major search engines, unscrupulous people began abusing the tags by passing keywords that had little or nothing to do with the content of their sites, and the search engines began to reduce using that content for a keyword association ranking factor because it couldn’t be trusted. Eventually, search engines pretty well dropped using them for ranking altogether and newer search engines didn’t bother to use them at all, leading Danny Sullivan to declare the death of the metatags in 2002.
Fast forward to 2006, and the situation has changed yet again. Your meta tag content can once again directly affect your pages’ rankings in the SERPs!
Possible Related Posts
Posted by Chris of Silvery on 11/09/2006
Permalink | | Print
| Trackback | Comments Off on Nouveau Meta Tags for SEO | Comments RSS
Filed under: Search Engine Optimization, SEO, Tricks Google, meta-tags, metatags, msn, Search Engine Optimization, SEO, Yahoo
Hey Digg! Fix your domain name for better SEO traffic!
Hey, Digg.com team! Are you aware that your domain names aren’t properly canonized? You may be losing out on good ranking value in Google and Yahoo because of this!
Even if you’re not part of the Digg technical team, this same sort of scenario could be affecting your site’s rankings. This aspect of SEO is pretty simple to address, so don’t ignore it and miss out on PageRank that should be yours. Read on for a simple explanation.
Possible Related Posts
Posted by Chris of Silvery on 10/04/2006
Permalink | | Print
| Trackback | Comments Off on Hey Digg! Fix your domain name for better SEO traffic! | Comments RSS
Filed under: Search Engine Optimization, SEO, Social Media Optimization, URLs digg, Google, PageRank, SEO, url-canonization, Yahoo

