Interview with Google about duplicate content
The following is an excerpt of a video conversation held between Vanessa Fox, Product Manager of Google Webmaster Central, and Rand Fishkin, CEO and co-founder of SEOMoz about Google and duplicate content. This further confirms Adam Lasnik’s position that it’s a filter, not a penalty. The full video can be found here.
Rand Fishkin: Duplicate content filter, is that the same or different to a duplicate content penalty?
Vanessa Fox: So I think there is a lot of confusion about this issue. I think people think that if Google sees information on a site that is duplicate within the site then there will some kind of penalty applied (duplicating its own material). There’s a couple of different ways this can happen, one if you use subpages that seem to have a lot of content that is the same, e.g. a local type site that says here is information about Boulder and here’s information about Denver, but it doesn’t actually have any information about Boulder, it just says Boulder in one place and Denver in the other. But otherwise the pages are exactly the same. Another scenario is where you have multiple URL’s that point to the same exact page, e.g. a dynamic site. So those are two times when you have duplicate content within a site.Fishkin: So would you call that a filter or would you call that a penalty, do you discriminate between the two?
Fox: There is no penalty. We don’t apply any kind of penalty to a site that has that situation. I think people get more worried than they should about it because they think oh no, there’s going to be a penalty on my site because I have duplicate content. But what is going to happen is some kind of filtering, because in the search results page we want to show relevant, useful pages instead of showing ten URLs that all point to the same page – which is probably not the best experience for the user. So what is going to happen is we are going to only index one of those pages. So if you don’t care, in the instance where there are a lot of URLs that all point to the same exact page, if you don’t care which one of them is indexed then you don’t have to do anything, Google will pick one and we’ll index it and it will be fine.Fishkin: So let’s say I was looking for the optimal Google experience and I was trying to optimize my site to the best of my ability, would I then say well maybe it isn’t so good for me to have Google crawling my site pages I know are duplicates (or very similar), let me just give them the pages I know they will want?
Fox: Right, so you can do that, you can redirect versions…we can figure it out, it’s fine, we have a lot of systems. But if you care which version of the site is indexed, and you don’t want us to hit your site too much by crawling all these versions, then yeah, you might want to do some things, you can submit sitemaps and tell us which version of the page you want, you can do a redirect, you can block with robots, you can not serve us session IDs. I mean there’s a lot of different things you could do in that situation. In the situation where the pages are just very similar, it’s sort of a similar situation where you want to make the pages as unique as possible. So that’s sort of a different solution to the similar sort of problem. You want to go, ok, how can I make my page about Boulder, different from my page about Denver, or maybe I just need one page about Colorado if I don’t have any information about the other two pages.
Possible Related Posts
Posted by Gabriel of Gabriel on 12/28/2006
Permalink | |  Print
| Trackback | Comments Off on Interview with Google about duplicate content | Comments RSS
Print
| Trackback | Comments Off on Interview with Google about duplicate content | Comments RSS
Filed under: Google duplicate-content, duplicate-pages, Google, Vanessa-Fox, Webmaster-Central
Google, Yahoo & MicroSoft to Cooperate on Sitemaps
I was delighted today that the Google and Yahoo search engines announced at PubCon that they would jointly support and collaborate upon one protocol for webmasters to use for submitting their site URLs for potential inclusion. View the video of the announcement here. MicroSoft has also apparently agreed to use the same protocol as well.
To support this initiative, they will jointly support sitemaps.org. If you recall, “sitemaps” was the product name that Google had been using, and which became deprecated just a few months ago in favor of “Google Webmaster Tools”. Obviously, the wheels had already begun turning to repurpose the “Sitemaps” brand name into a jointly-operated service.
Now when Sitemaps are generated to follow the common protocol, webmasters will still need to submit the link feeds to each of the SEs via their existing managment tools such as in Google Webmaster Tools and in Yahoo! Site Explorer.
If you recall, I was one of a number of webmasters out there who had requested that they collaborate on a common protocol, such as in a blog post I wrote back in September:
“Hopefully each of the major search engines will try to employ identical or compatible formats for site URLs, because it will be a hassle to have to keep up with multiple formats. This is an area where the SEs really ought to cooperate with one another for “pro bono publicoâ€? – for the common good. Currently, Yahoo seems to be just defensively immitating Google in this arena, and no one’s showing signs of collaborating.”
Kudos to Google and Yahoo for overcoming traditional corporate competitiveness to do something that mutually benefits website owners as well as the search engines!
Â
Possible Related Posts
Posted by Chris of Silvery on 11/16/2006
Permalink | | Print
| Trackback | Comments Off on Google, Yahoo & MicroSoft to Cooperate on Sitemaps | Comments RSS
Filed under: Google, MSN Search, Tools, Yahoo Google, msn, Site-Explorer, site-submission, Sitemaps, Yahoo
SEO May Be Eclipsed by User-Centered Design
I’ve been seeing indications that Google has shifted their weighting of the ~200 various signals they use in their ranking soup over the past couple of years. It used to be that PageRank along with the number of keyword references on a page were some of the strongest signals used for what page comes up highest in the search results, but I’ve seen more and more cases where PageRank and keyword density seem relatively weaker than they once were. I see a lot of reasons to believe that quality ratings have become weighted more heavily for rankings, particularly among more popular search keywords. Google continues to lead the pack in the search marketplace, so their evolution will likely influence their competitors in similar directions, too.
So, what is my evidence that Google’s development of Quality criteria is becoming more influential in their rankings than PageRank and other classic optimization elements? Read on and I’ll explain. (more…)
Possible Related Posts
Posted by Chris of Silvery on 11/15/2006
Permalink | | Print
| Trackback | Comments Off on SEO May Be Eclipsed by User-Centered Design | Comments RSS
Filed under: Best Practices, Design, Google, PageRank, Search Engine Optimization, SEO, Yahoo Google, IndyRank, SEO, TrustRank, usability, User-Centered-Design, Yahoo
Google Book Search: Not a Threat to Publishing
It’s not surprising that large chunks of the book publishing industry have gotten up in arms ever since Google announced its intentions to scan the world’s books and make them available online for free. After all, the publishing industry is not really known for adopting modern practices all that quickly. Book publishing is a grand old industry, and top publishing houses seem more invested in preserving the status quo than in adapting for the changing world.

But, when the publishing industry got up in arms against Google’s plans to facilitate the searching of books, their knee-jerk reaction against the new paradigm caused them to miss the fact that Google’s basic proposal really isn’t all that revolutionary. There’s another institution that has taken published books and made them available to the public. For Free. For thousands of years. Libraries!
Possible Related Posts
Posted by Chris of Silvery on 10/08/2006
Permalink | | Print
| Trackback | Comments Off on Google Book Search: Not a Threat to Publishing | Comments RSS
Filed under: General, Google, Searching Amazon.com, book-search, Google-Book-Search, Publishing-Industry
Putting Keywords in Your URLs
Recently Matt Cutts blogged that:
doing the query [site:windowslivewriter.spaces.live.com] returns some urls like windowslivewriter.spaces.live.com /Blog/cns!D85741BB5E0BE8AA!174.entry . In general, urls like that sometimes look like session IDs to search engines. Most bloggy sites tend to have words from the title of a post in the url; having keywords from the post title in the url also can help search engines judge the quality of a page.
He then clarified his statement above, in the comments of that post:
Tim, including the keyword in the url just gives another chance for that keyword to match the user’s query in some way. That’s the way I’d put it.
What does this mean? It means that from Google’s perspective, keywords in your URLs are a useful thing to have. It’s another “signal” and can provide ranking benefits.
How should you separate these keywords? Not with underscores, that’s for sure. Matt Cutts has previously gone on the record to say that Google does not treat underscores as word separators. Use hyphens instead. Or plus signs would be okay too.
Also, I’d avoid too many hyphens in the URL, as that can look spammy. Try to keep it to three or fewer. Unless your site is powered by WordPress, in which case Google probably makes an exception for that, given how popular it is and how many legitimate bloggers have loads of hyphens in their permalink URLs. By the way, you can trim those down using the Slug Trimmer plugin for WordPress.
Possible Related Posts
Posted by stephan of stephan on 09/20/2006
Permalink | | Print
| Trackback | Comments Off on Putting Keywords in Your URLs | Comments RSS
Filed under: Google, URLs keywords, SEO, URLs
To Use Sitemaps, or Not To Use Sitemaps, That’s the Question
It was really great when Google launched its Sitemaps (recently renamed to Webmaster Tools, as part of their Webmaster Central utilities) – when that happened it was a really great indication of a new time where technicians who wished to help make their pages findable would not automatically be considered “evil” and the SEs might provide tools to help technicians disclose their pages directly. Yahoo soon followed with their own tools, named Yahoo! Site Explorer, and surely MSN will bow to peer pressure with their own submission system and tools.
Initially, I thought that there wasn’t significant advantage to me for using these systems, because I’d already developed good methods for providing our page links to the search engines through the natural linking found in our site navigation systems.
Why should I expend yet more time and resources to dynamically produce the link files?
Possible Related Posts
Posted by Chris of Silvery on 09/19/2006
Permalink | | Print
| Trackback | Comments Off on To Use Sitemaps, or Not To Use Sitemaps, That’s the Question | Comments RSS
Filed under: General, Google, Site Structure, Yahoo Google-Sitemaps, google-webmaster-tools, Sitemaps, URL-submission, yahoo-site-explorer
Will Google Keep Minority Report from Happening? Eric Schmidt’s Chat with Danny Sullivan
This morning at the Search Engine Strategies Conference 2006 in San Jose, Danny Sullivan interviewed the Google CEO, Eric Schmidt, in the conference’s main keynote session. Others such as the Search Engine Roundtable have reported on most of the content of that session, but one little thing Danny mentioned particularly grabbed my attention. Read on, and I’ll elaborate….

Possible Related Posts
Posted by Chris of Silvery on 08/09/2006
Permalink | | Print
| Trackback | Comments Off on Will Google Keep Minority Report from Happening? Eric Schmidt’s Chat with Danny Sullivan | Comments RSS
Filed under: Conferences, Futurism, General, Google, Security, technology cyberpunk, danny-sullivan, Eric-Schmidt, Google, Philip-K.-Dick, PKD, privacy, SES-Conference
A window into Google through error messages: PageRank vectors and IndyRank
There’s been plenty of speculation posted to the blogosphere on the recently discovered cryptic Google error message; my favorites being from Wesley Tanaka and from Teh Xiggeh.
What intrigues me most in the Google error message is the references to IndyRank and to PageRank possibly being a vector. In regards to IndyRank, Stuart Brown suspects it means an ‘independent ranking’ — a “human-derived page ranking scoring, independent of the concrete world of linking and keywords”.
In regards to a PageRank vector, Wesley hypothesizes:
“If page rank is actually a vector (multiple numbers) as opposed to a scalar (single number) like everyone assumes (and like is displayed by the toolbar). It would make sense — the page rank for a page could store other aspects of the page, like how likely it is to be spam, in addition to an idea of how linked-to the page is. The page rank you see in the google toolbar would be some scalar function of the page rank vector.”
Of course the Google engineers are probably laughing at all this.
Possible Related Posts
Posted by stephan of stephan on 07/22/2006
Permalink | | Print
| Trackback | Comments Off on A window into Google through error messages: PageRank vectors and IndyRank | Comments RSS
Filed under: Google, PageRank Google, IndyRank, PageRank, vectors
Toolbar PageRank Update
Yep, it’s that time again.
I don’t usually care that much, but we had a little snafu with our PageRank readout on the toolbar for our netconcepts.com site due to a misconfiguration on our end (detailed on my post “Toolbar PageRank Update Is Currently Underway)”, and happily that’s now corrected.
Possible Related Posts
Posted by stephan of stephan on 07/14/2006
Permalink | | Print
| Trackback | Comments Off on Toolbar PageRank Update | Comments RSS
Filed under: Google, PageRank Google, Google-Toolbar, PageRank
Google Sitemaps Reveal Some of the Black Box
I earlier mentioned the recent Sitemaps upgrades which were announced in June, and how I thought these were useful for webmasters. But, the Sitemaps tools may also be useful in other ways beyond the obvious/intended ones.
The information that Google has made available in Sitemaps is providing a cool bit of intel on yet another one of the 200+ parameters or “signals” that they’re using to rank pages for SERPs.
For reference, check out the Page Analysis Statistics that are provided in Sitemaps for my “Acme” products and services experimental site:
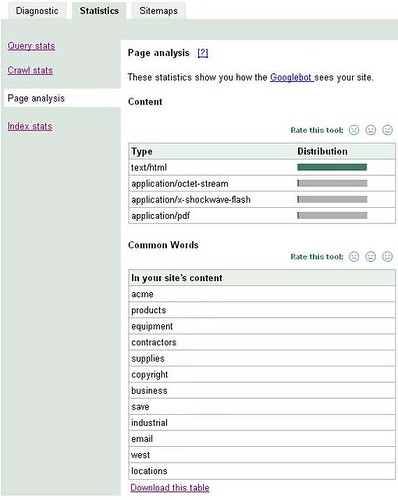
It seems unlikely to me that these stats on “Common Words” found “In your site’s content” were generated just for the sake of providing nice tools for us in Sitemaps. No, the more likely scenario would seem to be that Google was already collating the most-common words found on your site for their own uses, and then they later chose to provide some of these stats to us in Sitemaps.
This is significant, because we’ve already known that Google tracks keyword content for each page in order to assess its relevancy for search queries made with that term. But, why would Google be tracking your most-common keywords in a site-wide context?
One good explanation presents itself: Google might be tracking common terms used throughout a site in order to assess if that site should be considered authoritative for particular keywords or thematic categories.
Early on, algorithmic researchers such as Jon Kleinberg worked on methods by which “authoritative” sites and “hubs” could be identified. IBM and others did further research on authority/hub identification, and I heard engineers from Teoma speak on the importance of these approaches a few times at SES conferences when explaining the ExpertRank system their algorithms were based upon.
So, it’s not all that surprising that Google may be trying to use commonly-occuring text to help identify Authoritative sites for various themes. This would be one good automated method for classifying sites for subject matter categories and keywords.
The take-away concept is that Google may be using words found in the visible text throughout your site to assess whether you’re authoritative for particular themes or not.
Â
Possible Related Posts
Posted by Chris of Silvery on 07/11/2006
Permalink | | Print
| Trackback | Comments Off on Google Sitemaps Reveal Some of the Black Box | Comments RSS
Filed under: Google, Tools Algorithms, Authoritative-Hubs, ExpertRank, Google, Hubs, Keyword-Classification, On-Page-Factors, PageRank, Search Engine Optimization, SEO, Sitemaps

